


https://doi.org/10.1109/TVT.2022.3228198
研究背景
- 现有的分配算法忽略了初始状态造成通信和资源的浪费
- 拍卖分配和博弈论的方式均需要进行多轮全局通信造成通信负担较重
因此提出一个双向的请求-响应机制,从而通过局部的 UAV 通信降低全局的通信量,采用 MARL 的网络以及经验回放,使用 Q-learning 和参数共享加快模型的训练
问题建模
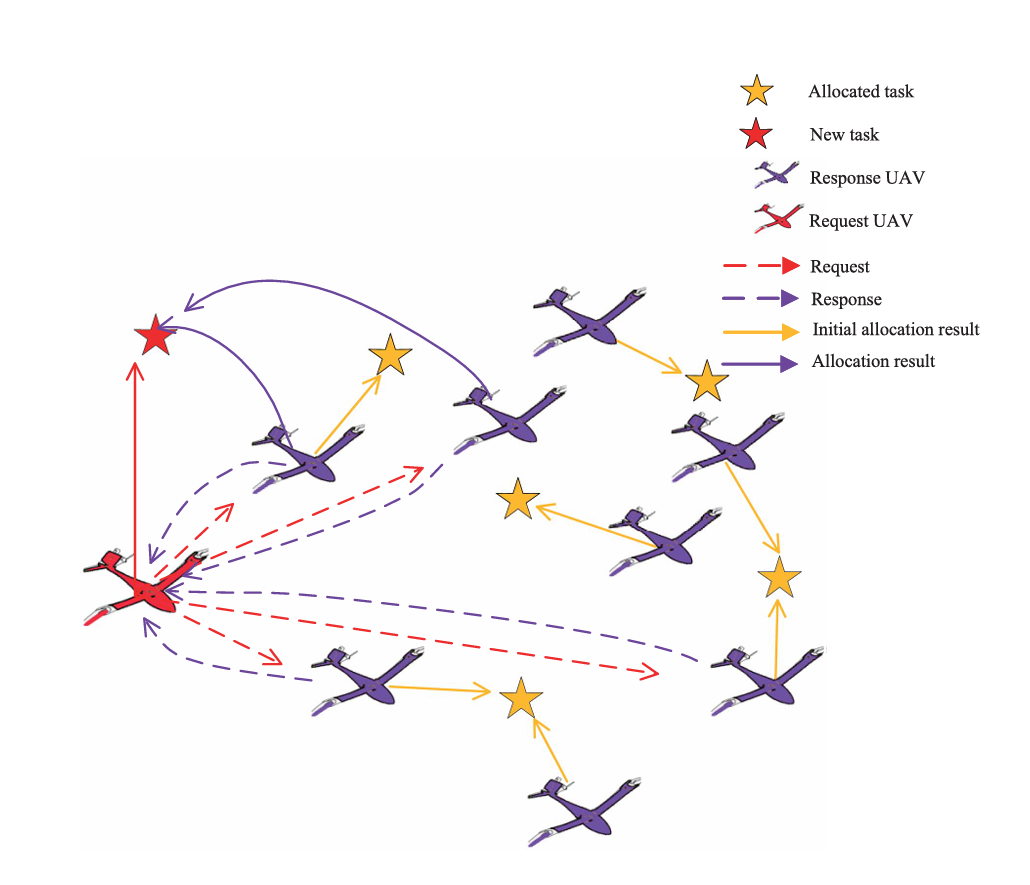
在一个由若干架 UAV 和目标组成的一个环境中(UAV 数目大于任务数目,初始任务分配中每个任务的 UAV 资源是冗余的,即使部分 UAV 被重新分配给新任务后,剩余资源仍然可以满足原任务需求。),为 UAV 分配好初始的任务,此时 Request UAV 发现了一个新的任务,向其他 UAV 发送 Requeset,接收到 Request 后,Response UAV 根据目标的重要性,紧急度以及距离等进行评估,然后向 Request UAV 发送 Response 作为返回结果,根据接收到的结果,Request UAV 决定哪些 Response UAV 将参与这个 Task 的执行
每一个 UAV 有自己的能力组合,如侦察,轰炸,通信等,而每一个任务有不同的能力需求,因此在分配过程中,需要分配的 UAV 能力足以完成任务,且到任务地点的距离和最短,另外为了确保高效的分配,还需使得分配的能力尽可能的贴近 Task 的需求
选中的 UAV 集合需要在 attack、reconnaissance、jamming、communication、bombing 五个维度上满足任务需求,同时能力冗余不能超过阈值 Th,并尽量最小化到新任务的总距离。选出来的 UAV 能力既要大于任务需求,又不能超出太多。
MDP 设计
Request UAV
状态空间
新分配的任务信息以及 UAV 的信息
动作空间
完成这个新 Task 的 UAV 集合
奖励函数
如果分配的 UAV 满足边界条件,则奖励为 rp−λ∑dis(Ui,Tnew)r_p-\lambda\sum dis(U_{i}, T_{new})rp−λ∑dis(Ui,Tnew)
否则惩罚为 −rp-r_{p}−rp
Response UAV
状态空间
新任务需求、当前正在执行任务需求、新任务重要性、燃料/距离代价
动作空间
是否参与新任务
奖励函数
rr = δk(Imp_new - Imp_old)
UAV 如果从低重要度旧任务转向高重要度新任务,会获得更高收益;同时还会扣除到新任务的距离成本
引入了 $\varepsilon - greedy$ 策略使得其有概率探索其他操作,从而防止陷入局部最优
graph TD
Proposer_UAV --> New_Task
New_Task --> Select_Responser
Select_Responser --> Get_Q_value
Get_Q_value --> Select_higher_Q
训练技巧
mark
- 参数共享
- target network
- PER
- 多智能体 TD-error 优先级
- importance sampling 修正
讨论与分析
虽然说整个系统通过局部分配的模式完成了去中心化,但是从任务重分配的流程来说,貌似通信的开销并未得到缩减,在 Request UAV 的状态感知中仍然需要获取全局其他 UAV 的状态,并向其他 UAV 发送任务请求得到回复,该方法降低的可能是“重复重规划”和“全体多轮协商”的开销,而不是严格意义上的“状态获取通信开销”。论文没有显式定义通信开销指标,也没有给出消息数量、通信半径、带宽限制、丢包率或拓扑连通性下的对比实验,因此“降低通信负担”的论证还不够充分,文中并未对二者之间进行对比和性能分析
另外只考虑能力、距离、燃料阈值,没有通信链路建模
如果针对通信方面进行改进的话,可能需要将动作空间转变为连续的动作空间,从而控制发送功率,压缩率等
模型的训练方面的一些优化和技巧可以参考

评论