


https://doi.org/10.1109/TWC.2022.3153316
研究背景
- UAV 和 UE 都在不断移动,通信链路不断变化
- 如果 UAV 和 UE 数量增加,管理的状态数也会增多导致协同效率低
因此使用任务卸载的方式优化整个系统,并用 MADRL 来解决 UAV 的轨迹,任务分配以及通信资源管理,UE 的计算任务先上传到 UAV,然后由 UAV 决定一部分在 UAV 本地计算,另一部分继续转发到 EC 计算
系统模型
环境中存在 UAV,UE 和 EC,UAV 划分了工作子区域,各个子区域之间没有重叠,所有 UAV 都连接到一个中心云服务器,论文假设 UE 不能本地计算,因此所有任务都要先卸载到 UAV
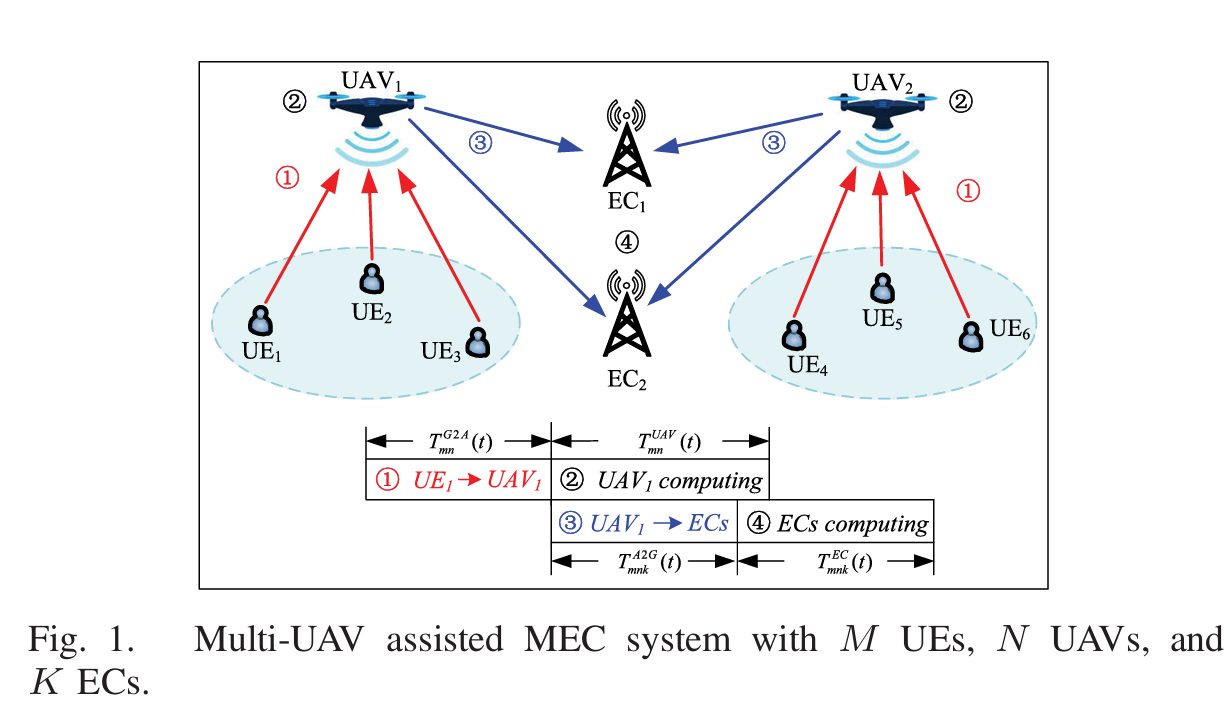
UAV 运动模型
设 UAV 在 t 时刻的坐标为 $x_{n}(t),y_{n}(t),z_{n}(t)$,覆盖范围仰角 $\phi_{n}$,则可得到覆盖半径 $C_{max}=z_{n}(t)\tan(\phi_{n})$,另外 xyz 三个坐标在边界上均有限制
为了防止两个 UAV 的覆盖范围重叠以及两个 UAV 之间相撞,对其速度以及距离做出约束 $||v_{n}(t)-v_{j}(t)|| \ge [C_{max}^n(t)+C_{max}^j(t)]$,以及 $||\omega_{n}(t) - \omega_{j}(t) \ge D_{min}||$
空对地信道模型
采用自由空间衰落模型
$$h(t)=\frac{g_{0}}{d_{mn}(t)^2}$$
根据香农公式可以得到传输速率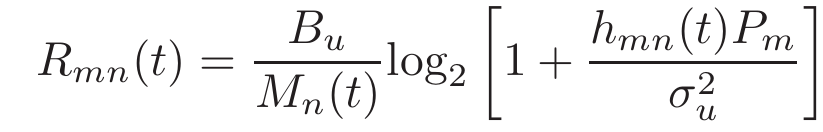
进而计算传输时延以及能量消耗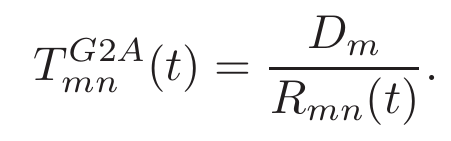
UAV 到 EC 的信道建模类似
最终的优化问题转换为能量和时延的加权,优化对象为 UAV 的位置以及 UAV 和 EC 的边缘计算分工比例
MDP 建模
状态空间
所有 UAV 的位置
动作空间
飞行距离,方位角,垂直飞行距离,传输功率,任务分配比率
奖励函数
如果满足所有的约束条件,则设置为系统开销的负值,如果有条件不满足,如 UAV 重叠,UE 未被覆盖等,则进行惩罚
使用 MATD 3 进行优化,从训练结果可以看到 reward 从一开始的极大负数逐渐收敛至 0
mark 其中的优化以及训练技巧也许可以借鉴一下
讨论与分析
这篇文章考虑的信道模型比较简单,采用自由空间衰落信道进行计算
论文将状态简化为 UAV 的三维坐标,但 reward 和 transition 事实上依赖 UE 位置、任务规模、信道状态和计算资源,因此状态空间设计偏简化。
不过 MATD 3 的训练和优化过程可以借鉴一下
使用 MATD 3 输出连续的动作空间,从而可以对功率以及分配等进行精确的控制,在奖励函数的设计上也许可以有所启发

评论