


https://doi.org/10.1109/TASE.2024.3358894
研究背景
- UAV 的 task 分配可以视为一个 NP-Hard 问题
- 传统的精确求解在规模变大时计算量会急剧增大,近似求解需要在精度和时间中权衡
因此提出了一个 2 层的 DRL 模型,并将 UAV 调度任务分解为任务分配和路径规划两个子任务进行求解
问题建模
考虑一个由 V 个 UAV 的场景,初始都位于同一位置,区域内存在 N 个独立的任务,UAV 需要试图最大化完成任务,假设 UAV 的速度恒定且高度恒定
假定一个 Task 只由一个 UAV 执行,并且 UAV 的飞行距离不能超过 限值,不走回头路
最终任务是最大化执行的任务价值
提出的方法
将其分为两个子问题,任务划分以及路径规划,分别采用 MDP 进行求解
上层网络将 Task 分割为不同的子集,下层网络在这些子集中选择合适的路径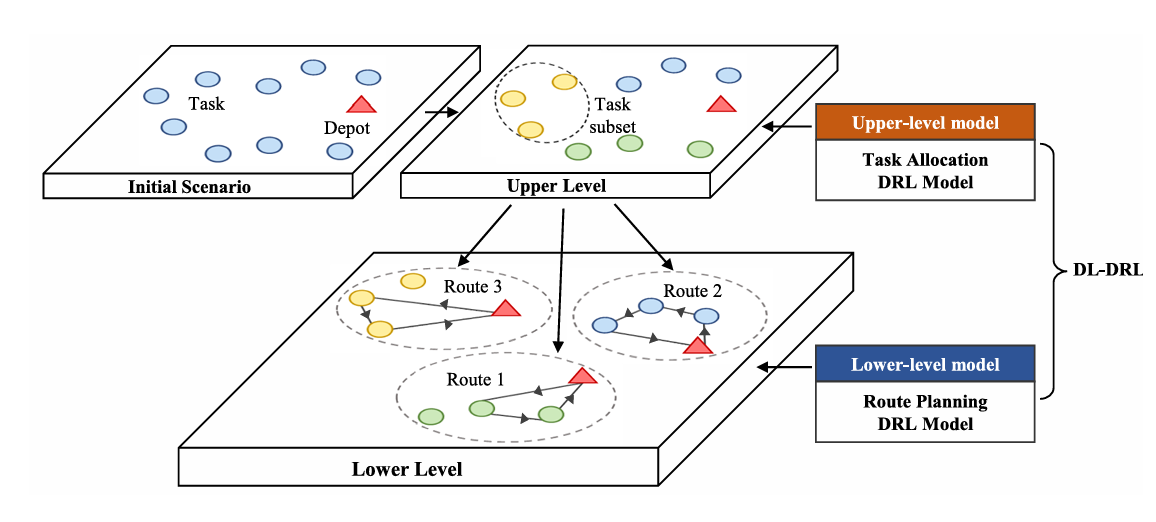
上层模型 MDP
状态空间
包含已经分配的任务 $V_{t}$ 和需要分配的任务 $m_{t}$
动作空间
需要将任务 $m_{t}$ 分配给的 UAV
状态转移
为了方便训练,任务分配完成后,假设 $m_{t}$ 分配给了 UAV i,那么在其任务列表后加上 $m_{t}$,在其他 UAV 的任务列表里重复最后一个任务,从而保证任务列表的长度对齐
奖励函数
所有 UAV 完成的 Task 的 value 总和
模型实现
将任务视为一个序列,使用 Transformer 的 Encoder-Decoder 结构
下层模型 MDP
状态空间
UAV 的任务列表,包含任务位置和任务价值,UAV 当前位置以及剩余飞行距离
动作空间
下一个要去完成的任务
状态转移
减去飞行距离,将已完成的任务价值设置为 0
奖励函数
最大化执行的任务数量
训练技巧
ITS
因为涉及上下两层模型,因此如果一起训练可能会导致效果不理想
文中是先预训练下层模型,使其初步具备路径规划的能力,然后训练上层模型,下层阶段性更新,最后再进行上下层的交替训练,从而达到较好的效果
mark 在我们这边的话也是类似的,JSCC 和 MATD 3 需要分开进行训练,目前使用的是类似拟合的方式,也许等到两边都初步训练出一个较好的效果后再进行联调会达到更好的效果
讨论与分析
文章整体思路是将任务分配和路径规划分为两个部分进行解决,但是貌似只能针对静态的任务需求,如果在执行过程中出现了新的任务则无法进行重新规划,另外其网络结构决定了 UAV 的数量是固定的,如果发生变动可能需要重新训练模型?
分层训练的思路和目前做的是类似的,其他的可能参考意义不大

评论