搜索到
4
篇与
的结果
-
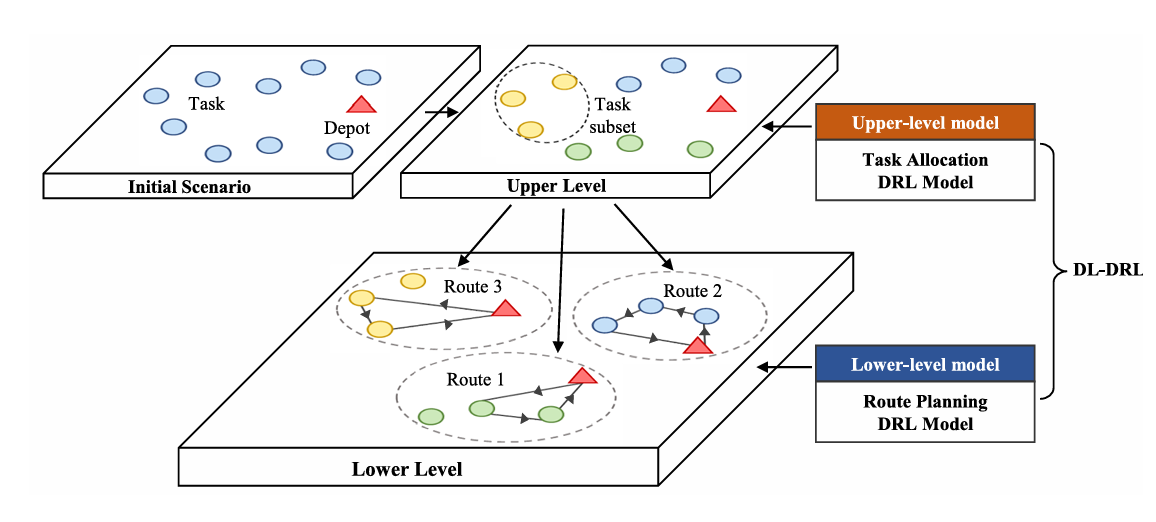
 阅读笔记:DL-DRL A Double-Level Deep Reinforcement Learning Approach for Large-Scale Task Scheduling of Multi-UAV https://doi.org/10.1109/TASE.2024.3358894研究背景UAV 的 task 分配可以视为一个 NP-Hard 问题传统的精确求解在规模变大时计算量会急剧增大,近似求解需要在精度和时间中权衡因此提出了一个 2 层的 DRL 模型,并将 UAV 调度任务分解为任务分配和路径规划两个子任务进行求解问题建模考虑一个由 V 个 UAV 的场景,初始都位于同一位置,区域内存在 N 个独立的任务,UAV 需要试图最大化完成任务,假设 UAV 的速度恒定且高度恒定假定一个 Task 只由一个 UAV 执行,并且 UAV 的飞行距离不能超过 限值,不走回头路最终任务是最大化执行的任务价值提出的方法将其分为两个子问题,任务划分以及路径规划,分别采用 MDP 进行求解上层网络将 Task 分割为不同的子集,下层网络在这些子集中选择合适的路径上层模型 MDP状态空间包含已经分配的任务 $V_{t}$ 和需要分配的任务 $m_{t}$动作空间需要将任务 $m_{t}$ 分配给的 UAV状态转移为了方便训练,任务分配完成后,假设 $m_{t}$ 分配给了 UAV i,那么在其任务列表后加上 $m_{t}$,在其他 UAV 的任务列表里重复最后一个任务,从而保证任务列表的长度对齐奖励函数所有 UAV 完成的 Task 的 value 总和模型实现将任务视为一个序列,使用 Transformer 的 Encoder-Decoder 结构下层模型 MDP状态空间UAV 的任务列表,包含任务位置和任务价值,UAV 当前位置以及剩余飞行距离动作空间下一个要去完成的任务状态转移减去飞行距离,将已完成的任务价值设置为 0奖励函数最大化执行的任务数量训练技巧ITS因为涉及上下两层模型,因此如果一起训练可能会导致效果不理想文中是先预训练下层模型,使其初步具备路径规划的能力,然后训练上层模型,下层阶段性更新,最后再进行上下层的交替训练,从而达到较好的效果mark 在我们这边的话也是类似的,JSCC 和 MATD 3 需要分开进行训练,目前使用的是类似拟合的方式,也许等到两边都初步训练出一个较好的效果后再进行联调会达到更好的效果讨论与分析文章整体思路是将任务分配和路径规划分为两个部分进行解决,但是貌似只能针对静态的任务需求,如果在执行过程中出现了新的任务则无法进行重新规划,另外其网络结构决定了 UAV 的数量是固定的,如果发生变动可能需要重新训练模型?分层训练的思路和目前做的是类似的,其他的可能参考意义不大
阅读笔记:DL-DRL A Double-Level Deep Reinforcement Learning Approach for Large-Scale Task Scheduling of Multi-UAV https://doi.org/10.1109/TASE.2024.3358894研究背景UAV 的 task 分配可以视为一个 NP-Hard 问题传统的精确求解在规模变大时计算量会急剧增大,近似求解需要在精度和时间中权衡因此提出了一个 2 层的 DRL 模型,并将 UAV 调度任务分解为任务分配和路径规划两个子任务进行求解问题建模考虑一个由 V 个 UAV 的场景,初始都位于同一位置,区域内存在 N 个独立的任务,UAV 需要试图最大化完成任务,假设 UAV 的速度恒定且高度恒定假定一个 Task 只由一个 UAV 执行,并且 UAV 的飞行距离不能超过 限值,不走回头路最终任务是最大化执行的任务价值提出的方法将其分为两个子问题,任务划分以及路径规划,分别采用 MDP 进行求解上层网络将 Task 分割为不同的子集,下层网络在这些子集中选择合适的路径上层模型 MDP状态空间包含已经分配的任务 $V_{t}$ 和需要分配的任务 $m_{t}$动作空间需要将任务 $m_{t}$ 分配给的 UAV状态转移为了方便训练,任务分配完成后,假设 $m_{t}$ 分配给了 UAV i,那么在其任务列表后加上 $m_{t}$,在其他 UAV 的任务列表里重复最后一个任务,从而保证任务列表的长度对齐奖励函数所有 UAV 完成的 Task 的 value 总和模型实现将任务视为一个序列,使用 Transformer 的 Encoder-Decoder 结构下层模型 MDP状态空间UAV 的任务列表,包含任务位置和任务价值,UAV 当前位置以及剩余飞行距离动作空间下一个要去完成的任务状态转移减去飞行距离,将已完成的任务价值设置为 0奖励函数最大化执行的任务数量训练技巧ITS因为涉及上下两层模型,因此如果一起训练可能会导致效果不理想文中是先预训练下层模型,使其初步具备路径规划的能力,然后训练上层模型,下层阶段性更新,最后再进行上下层的交替训练,从而达到较好的效果mark 在我们这边的话也是类似的,JSCC 和 MATD 3 需要分开进行训练,目前使用的是类似拟合的方式,也许等到两边都初步训练出一个较好的效果后再进行联调会达到更好的效果讨论与分析文章整体思路是将任务分配和路径规划分为两个部分进行解决,但是貌似只能针对静态的任务需求,如果在执行过程中出现了新的任务则无法进行重新规划,另外其网络结构决定了 UAV 的数量是固定的,如果发生变动可能需要重新训练模型?分层训练的思路和目前做的是类似的,其他的可能参考意义不大 -
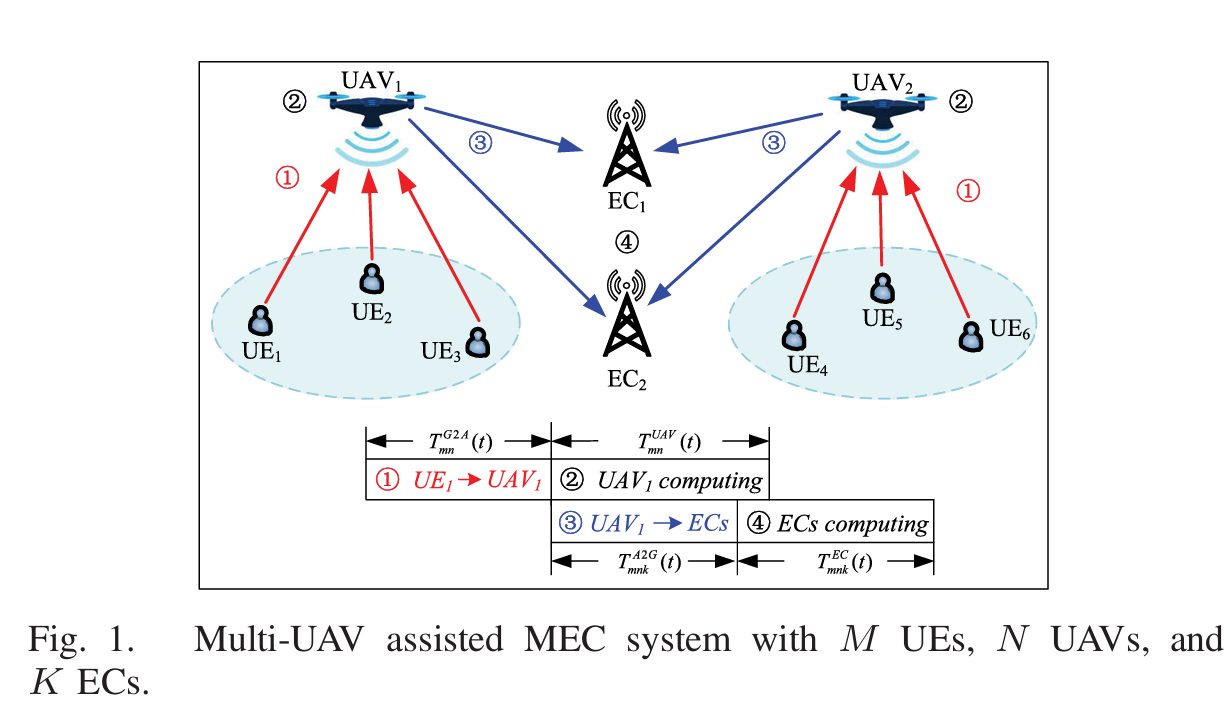
阅读笔记:Multi-Agent Deep Reinforcement Learning for Task Offloading in UAV-Assisted Mobile Edge Computing https://doi.org/10.1109/TWC.2022.3153316研究背景UAV 和 UE 都在不断移动,通信链路不断变化如果 UAV 和 UE 数量增加,管理的状态数也会增多导致协同效率低因此使用任务卸载的方式优化整个系统,并用 MADRL 来解决 UAV 的轨迹,任务分配以及通信资源管理,UE 的计算任务先上传到 UAV,然后由 UAV 决定一部分在 UAV 本地计算,另一部分继续转发到 EC 计算系统模型环境中存在 UAV,UE 和 EC,UAV 划分了工作子区域,各个子区域之间没有重叠,所有 UAV 都连接到一个中心云服务器,论文假设 UE 不能本地计算,因此所有任务都要先卸载到 UAVUAV 运动模型设 UAV 在 t 时刻的坐标为 $x_{n}(t),y_{n}(t),z_{n}(t)$,覆盖范围仰角 $\phi_{n}$,则可得到覆盖半径 $C_{max}=z_{n}(t)\tan(\phi_{n})$,另外 xyz 三个坐标在边界上均有限制为了防止两个 UAV 的覆盖范围重叠以及两个 UAV 之间相撞,对其速度以及距离做出约束 $||v_{n}(t)-v_{j}(t)|| \ge [C_{max}^n(t)+C_{max}^j(t)]$,以及 $||\omega_{n}(t) - \omega_{j}(t) \ge D_{min}||$空对地信道模型采用自由空间衰落模型$$h(t)=\frac{g_{0}}{d_{mn}(t)^2}$$根据香农公式可以得到传输速率进而计算传输时延以及能量消耗UAV 到 EC 的信道建模类似最终的优化问题转换为能量和时延的加权,优化对象为 UAV 的位置以及 UAV 和 EC 的边缘计算分工比例MDP 建模状态空间所有 UAV 的位置动作空间飞行距离,方位角,垂直飞行距离,传输功率,任务分配比率奖励函数如果满足所有的约束条件,则设置为系统开销的负值,如果有条件不满足,如 UAV 重叠,UE 未被覆盖等,则进行惩罚使用 MATD 3 进行优化,从训练结果可以看到 reward 从一开始的极大负数逐渐收敛至 0mark 其中的优化以及训练技巧也许可以借鉴一下讨论与分析这篇文章考虑的信道模型比较简单,采用自由空间衰落信道进行计算论文将状态简化为 UAV 的三维坐标,但 reward 和 transition 事实上依赖 UE 位置、任务规模、信道状态和计算资源,因此状态空间设计偏简化。不过 MATD 3 的训练和优化过程可以借鉴一下使用 MATD 3 输出连续的动作空间,从而可以对功率以及分配等进行精确的控制,在奖励函数的设计上也许可以有所启发
-
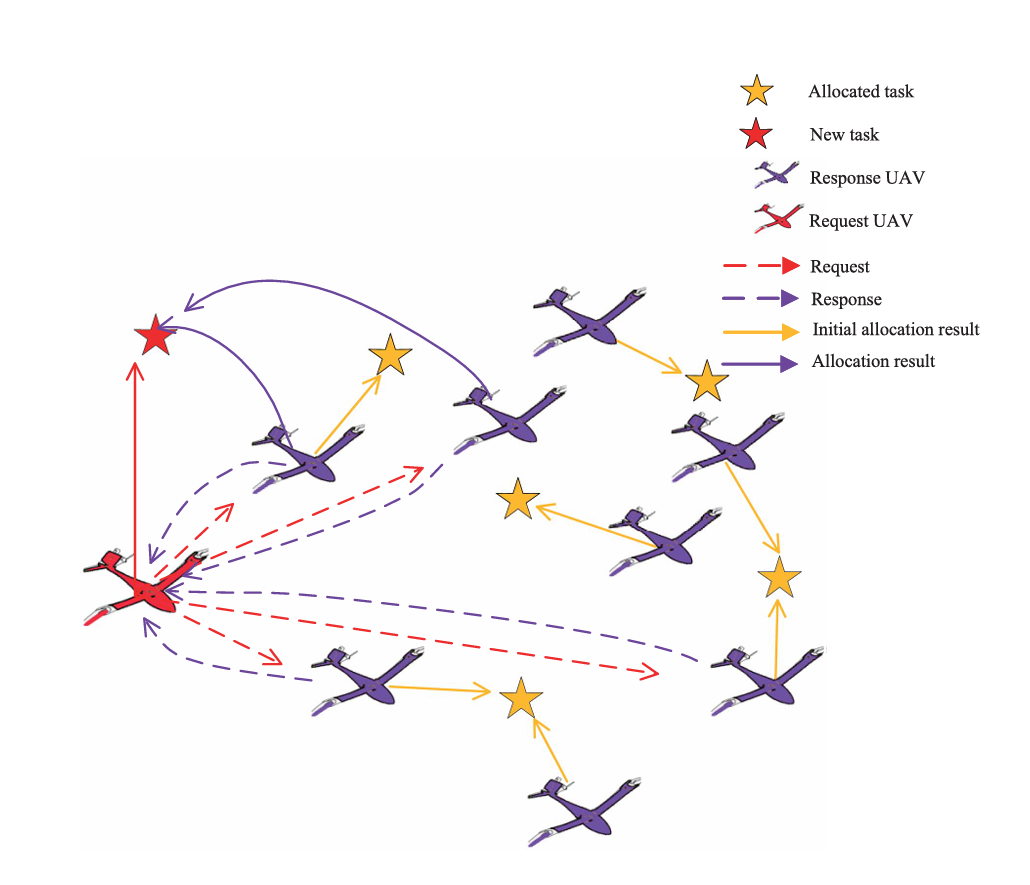
阅读笔记:Multi-Agent Reinforcement Learning-Based Coordinated Dynamic Task Allocation for Heterogenous UAVs https://doi.org/10.1109/TVT.2022.3228198研究背景现有的分配算法忽略了初始状态造成通信和资源的浪费拍卖分配和博弈论的方式均需要进行多轮全局通信造成通信负担较重因此提出一个双向的请求-响应机制,从而通过局部的 UAV 通信降低全局的通信量,采用 MARL 的网络以及经验回放,使用 Q-learning 和参数共享加快模型的训练问题建模在一个由若干架 UAV 和目标组成的一个环境中(UAV 数目大于任务数目,初始任务分配中每个任务的 UAV 资源是冗余的,即使部分 UAV 被重新分配给新任务后,剩余资源仍然可以满足原任务需求。),为 UAV 分配好初始的任务,此时 Request UAV 发现了一个新的任务,向其他 UAV 发送 Requeset,接收到 Request 后,Response UAV 根据目标的重要性,紧急度以及距离等进行评估,然后向 Request UAV 发送 Response 作为返回结果,根据接收到的结果,Request UAV 决定哪些 Response UAV 将参与这个 Task 的执行每一个 UAV 有自己的能力组合,如侦察,轰炸,通信等,而每一个任务有不同的能力需求,因此在分配过程中,需要分配的 UAV 能力足以完成任务,且到任务地点的距离和最短,另外为了确保高效的分配,还需使得分配的能力尽可能的贴近 Task 的需求选中的 UAV 集合需要在 attack、reconnaissance、jamming、communication、bombing 五个维度上满足任务需求,同时能力冗余不能超过阈值 Th,并尽量最小化到新任务的总距离。选出来的 UAV 能力既要大于任务需求,又不能超出太多。MDP 设计Request UAV状态空间新分配的任务信息以及 UAV 的信息动作空间完成这个新 Task 的 UAV 集合奖励函数如果分配的 UAV 满足边界条件,则奖励为 rp−λ∑dis(Ui,Tnew)r_p-\lambda\sum dis(U_{i}, T_{new})rp−λ∑dis(Ui,Tnew)否则惩罚为 −rp-r_{p}−rpResponse UAV状态空间新任务需求、当前正在执行任务需求、新任务重要性、燃料/距离代价动作空间是否参与新任务奖励函数rr = δk(Imp_new - Imp_old)UAV 如果从低重要度旧任务转向高重要度新任务,会获得更高收益;同时还会扣除到新任务的距离成本引入了 $\varepsilon - greedy$ 策略使得其有概率探索其他操作,从而防止陷入局部最优 graph TD Proposer_UAV --> New_Task New_Task --> Select_Responser Select_Responser --> Get_Q_value Get_Q_value --> Select_higher_Q 训练技巧mark参数共享target networkPER多智能体 TD-error 优先级importance sampling 修正讨论与分析虽然说整个系统通过局部分配的模式完成了去中心化,但是从任务重分配的流程来说,貌似通信的开销并未得到缩减,在 Request UAV 的状态感知中仍然需要获取全局其他 UAV 的状态,并向其他 UAV 发送任务请求得到回复,该方法降低的可能是“重复重规划”和“全体多轮协商”的开销,而不是严格意义上的“状态获取通信开销”。论文没有显式定义通信开销指标,也没有给出消息数量、通信半径、带宽限制、丢包率或拓扑连通性下的对比实验,因此“降低通信负担”的论证还不够充分,文中并未对二者之间进行对比和性能分析另外只考虑能力、距离、燃料阈值,没有通信链路建模如果针对通信方面进行改进的话,可能需要将动作空间转变为连续的动作空间,从而控制发送功率,压缩率等模型的训练方面的一些优化和技巧可以参考
-
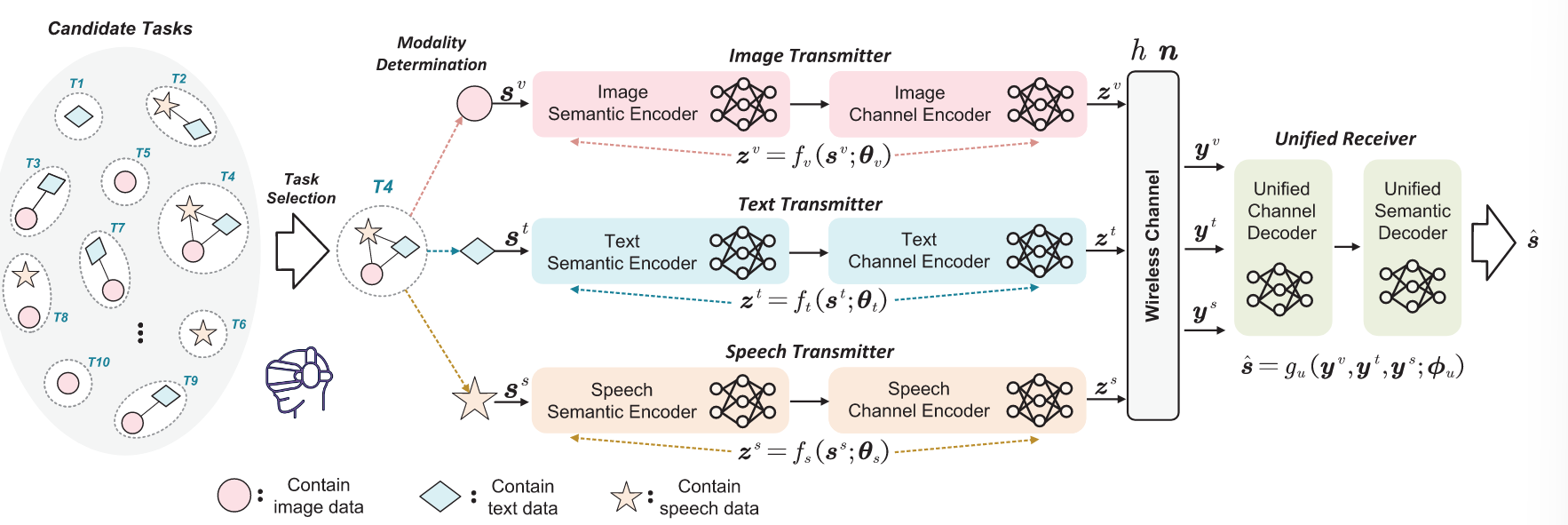
【阅读笔记】A Unified Multi-Task Semantic Communication System for Multimodal Data 现有的许多语义通信系统大多针对单任务单模型,很难处理不同的任务。不同任务需要不同的模型然而这对于有限资源的边缘设备来说是不现实的。因此文章提出了一种统一的基于深度学习的多任务语义通信模型U-DeepSC,可以完成文本、图像、语音的语义传输任务。文中假设了多种任务,文本、图像、语音以及其混合组成的任务,对于视频的处理则是将其转换为每一帧的图像然后作为图像任务处理在语义编码过程中针对数据的类型分别采用图像、文本、语音的语义编码和信道编码,解码过程中则使用统一的语义解码和信道解码器在编码器的编码层之间加入了FSM模块,用于逐层筛选有用的关键语义信息,同时可以根据信道的特征调整生成的语义信息的长度文中针对多种任务进行测试:文本情感分类、图像理解、视频情感分析、图像分类和图像重构、文本重构